- Para habilitar novamente as triggers:
SQL Server:
exec sp_MSforeachtable 'ALTER TABLE ? ENABLE TRIGGER ALL'
Oracle:
DECLARE
V_TRIGGER VARCHAR2 (200);
CID INTEGER ;
CURSOR OBJ IS
SELECT TRIGGER_NAME FROM USER_TRIGGERS ORDER BY TRIGGER_NAME;
BEGIN
OPEN OBJ;
FETCH OBJ INTO V_TRIGGER;
LOOP EXIT WHEN OBJ%NOTFOUND;
CID := DBMS_SQL.OPEN_CURSOR;
Dbms_Output.Enable (30000);
Dbms_Output.Put_Line ('Eliminando trigger ' || V_TRIGGER || '...');
DBMS_SQL.PARSE(cid, 'ALTER TABLE ' || TABLE_NAME || ' ENABLE TRIGGER ALL' , dbms_sql.v7);
FETCH OBJ INTO V_TRIGGER;
DBMS_SQL.CLOSE_CURSOR(CID);
END LOOP;
CLOSE OBJ;
END;
Retornar para Triggers.
8 - Atualização das estatísticas do banco de dados
As estatísticas coletadas pelo banco de dados propiciam um melhor desempenho para realizar pesquisas nas tabelas, através de um plano de execução mais eficiente, estatísticas desatualizadas podem degradar a performance do banco de dados.
Retornar para Atualização das estatísticas do banco de dados.
9 - "Auto create statistics" e "Auto update statistics"
As opções do database "Auto create statistics" e Auto update statistics podem levar a geração automática de um número grande de objetos de estatísticas, e o tempo necessário para sua atualização pelo banco de dados provavelmente implicará em perda de performance.
Retornar para "Auto create statistics" e "Auto update statistics".
10 - Limpeza de objetos temporários na base de dados
A limpeza periódica de registro de log e arquivo morto pode beneficiar bastante a execução de consultas e manipulação de dados nestas tabelas.
Retornar para Limpeza de objetos temporários na base de dados.
11 - Monitoramento do log do banco de dados
Problemas com a performance podem ter origem em eventos que são registrados no log do banco de dados, como por exemplo falhas na leitura de páginas do banco, deadlocks, etc, por isto recomendamos o monitoramento do log do banco de dados.
Retornar para Monitoramento do log do banco de dados.
12 - Reindexação periódica das tabelas
A reindexação periódica das tabelas é sumariamente necessária para o bom desempenho das aplicações, uma vez que este procedimento desfragmenta os índices das tabelas, proporcionando uma maior eficácia no processo de pesquisa no índice.
Retornar para Reindexação periódica das tabelas.
13 - Virtualização
A virtualização tem como objetivo ampliar a escabilidade do ambiente, mas pode gerar overhead no processamento dos dados, há duas maneiras de separar as aplicações SQL Server em unidades lógicas de isolamento. Um deles é para executar o SQL Server em várias instâncias dentro de um ambiente físico.
Outra maneira é executar o SQL Server dentro de um ambiente virtual, executando várias instâncias do SQL Server em um ambiente físico isolando cada instância no nível do aplicativo, em outras palavras, cabe a cada instância do SQL Server isolar os recursos do sistema, dados e segurança dos outros.
É importante notar que um dos benefícios de um ambiente virtual é que ele pode executar qualquer sistema operacional suportado pela aplicação da tecnologia virtual. Por exemplo, um ambiente virtual pode estar executando o Windows Server 2003, outro pode executar o Windows NT ® 4.0, e ainda um outro pode executar o Windows Server 2000. Um ambiente virtual consiste em uma ou mais máquinas virtuais.
O responsável pelo banco de dados da empresa deverá ficar atento ao virtualizar o servidor de banco de dados para não comprometer a performance do hardware, ou seja, sobrecarregar este servidor com vários ambientes virtualizados.
Retornar para Virtualização.
14 - Paralelismo
Atualmente, vivemos em uma era em que os microprocessadores são dominados por múltiplos núcleos, é recomendável sempre procurar explorar o paralelismo em banco de dados, a exploração de paralelismo deve ser considerada quando for necessário otimizar instruções SQL.
O SQL Server detecta automaticamente o melhor grau de paralelismo para cada instância de uma execução de consulta paralela operação DDL (linguagem de definição de dados) do índice. Isso é feito baseado nos seguintes critérios:
1 - Se o SQL Server estiver sendo executado em um computador que tenha mais de um microprocessador ou mais de uma CPU, como um computador SMP (multiprocessamento simétrico). Apenas computadores que têm mais de uma CPU podem usar consultas paralelas.
2 -Se houver threads suficientes disponíveis.
Cada operação de consulta ou índice exige um determinado número de threads para execução. A execução de um plano paralelo exige mais threads que um plano consecutivo, e o número de threads exigidos aumentam com o grau de paralelismo.
Quando o requisito de thread do plano paralelo de um grau específico de paralelismo não puder ser atendido, o Mecanismo de Banco de Dados diminuirá automaticamente o grau de paralelismo ou abandonará completamente o plano paralelo no contexto de carga de trabalho especificado. Depois, ele executará o plano consecutivo (um thread).
3 - O tipo de operação de consulta ou de índice executada.
As operações de índice que criam ou reconstroem um índice, ou descartam um índice cluster e as consultas que usam ciclos de CPU frequentemente são as melhores opções para um plano paralelo. Por exemplo, junções de tabelas grandes, agregações grandes e classificação de conjuntos de resultados grandes são boas alternativas. As consultas simples, frequentemente encontradas em aplicativos de processamento de transações, localizam a coordenação adicional exigida para executar consulta em paralelo que supera o aumento de desempenho potencial. Para distinguir as consultas que se beneficiam de paralelismo das que não se beneficia, o Mecanismo de Banco de Dados compara o custo estimado da execução da operação de consulta ou índice com o valor cost threshold for parallelism. Embora não recomendado, os usuários podem alterar o valor padrão 5 usando sp_configure.
4 - Se houver um número suficiente de linhas para processar.
Se o otimizador de consulta determinar que o número de linhas é muito baixo, não apresentará os operadores de troca para distribuir as linhas. Por conseguinte, os operadores serão executados em série. A execução dos operadores em um plano consecutivo evita cenários quando os custos de inicialização, distribuição e coordenação excedem os ganhos alcançados pela execução de operador paralela.
5 - Se as estatísticas de distribuição atuais estiverem disponíveis.
Se o grau mais alto de paralelismo não for possível, os graus inferiores serão considerados antes de o plano paralelo ser abandonado. Por exemplo, quando você criar um índice cluster em uma exibição, não poderão ser avaliadas estatísticas de distribuição, porque o índice cluster ainda não existirá. Nesse caso, o Mecanismo de Banco de Dados não poderá fornecer o grau mais alto de paralelismo para a operação de índice. Porém, alguns operadores, como de classificação e verificação, ainda poderão se beneficiar da execução paralela.
Retornar para Paralelismo.
15 - Avaliação de índices
Auditar e usar índices não é uma tarefa fácil, mas é fundamental para elevar a performance no banco de dados.
Tipos de avaliação:
Ø Indexes (Clustered)
Ø Indexes (Composição)
Ø Indexes (Covering)
Ø Indexes (Non-clustered)
Ø Indexes (Rebuild)
Ø Index Tuning Wizard
Retornar para Avaliação de Índices.
16 - Memória SQL
Deixar disponível o máximo de memória que poderá ser utilizada pelo SQL Server sem que isto atrapalhe outros processos que estiverem rodando no servidor, esta análise deverá ser feita pelo DBA da empresa.
1 - Acessar o Microsoft SQL Server conectando ao servidor, em seguida clicar com o botão direito sobre a instância e clicar em “Properties”:
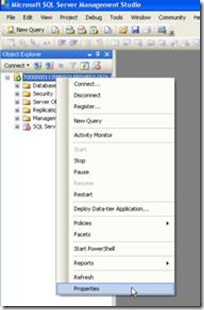 Image Modified
Image Modified
2 - Clicar na opção “Memory” e nos campos referente a Server memory options deverá preencher os campos Minimum server memory(in MB),este campo com o mínimo de memória que o Server irá utilizar e preencha também o campo Maximum server memory (in MB) com o máximo de memória que o Server poderá utilizar do servidor.
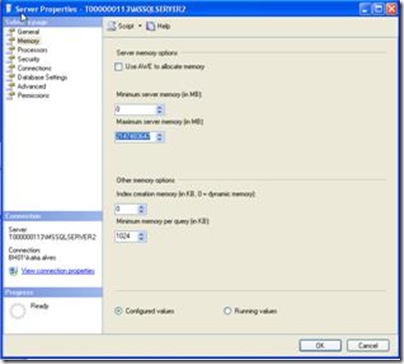 Image Modified
Image Modified
Retornar para Memória SQL.
17 - Processos bloqueados no banco de dados
O procedimento sp_who serve para ter uma visão geral sobre as conexões existentes e verificar se existe alguma conexão bloqueada (Block), está é uma tarefa que deverá ser executada pelo responsável pelo banco de dados na empresa.
Retornar para Processos bloqueados no banco de dados.
18 - Antivírus
Algumas rotinas nas aplicações utilizam-se de recursos temporários gravados em disco que são frequentemente recriados, gerando um número muito grande de acessos ao disco, e o monitoramento por um antivírus durante esta tarefa gera atrasos no processamento da aplicação.
Retornar para Antivírus.
19 - BDE
O BDE pode ser otimizado para beneficiar algumas rotinas da aplicação, mas uma vez que isto seja feito sem algum critério poderá incorrer na perda de performance para alocação e gerenciamento dos recursos de memória e CPU.
A utilização de valores muito altos para BLOB SIZE, BLOBS TO CACHE e MAXFILEHANDLES pode leva uma menor performance de algumas rotinas.
A necessidade de incrementar estes parâmetros se dar pelo volume de informações processadas em cache nestas rotinas.
No ambiente do DataCenter foi ajustado o parâmetro BLOB SIZE de 3000 para 512. Este parâmetro pode ser configurado com valores > 32 e < 1000, portanto o valor antigo era inválido.
Sugerimos as seguintes configurações:
Database:
BLOB SIZE = 512
BLOBS TO CHACHE = 1024
Configuration – Native – MSSQL:
TIMEOUT = 7200
Configuration – System – Init:
MAXFILEHANDLES = 2048
MEMSIZE = 205
Retornar para BDE.
20– TSS
TSS é o aplicativo que faz a intermediação do TOTVSSped com os vários tipos de banco de dados com os quais ele pode trabalhar.
São eles: DB2, MSSQL, Oracle, Informix, PostGres, MySQL.
O TopConnect deve ser instalado somente em uma estação. Por poder trabalhar com vários tipos de banco de dados não é necessário que o mesmo seja para a base do Corpore RM e apontado também não é necessário que o mesmo seja instalado em seu servidor de banco de dados. É aconselhada a criação de uma base de dados exclusiva para o SPED devido ao fato do processo gerar muitos registros e do serviço de consulta de autorização das notas ser executado com muita frequência nas suas tabelas.
Caso deseje ele pode apontar o TopConnect para sua base do Corpore RM. A escolha da base de dados e do banco para o SPED fica a cargo do cliente.
Uma vez definido o banco e a base a ser utilizada isto não poderá ser refeito sem a perda de dados da base do SPED.
Através do endereço www.suporte.totvs.com na área de download, para localizar o arquivo para download será necessário parametrizar o filtro da seguinte forma:
Linha : RM
Ambiente: RM-99.x
No campo Filtrar deverá digitar TSS.
Para orientação na configuração do TSS acesse nosso blog:
http://www.totvsconnect.blogspot.com/2010/12/dica-configuracao-tss.html
Retornar para TSS.




