Através do TOTVS News (módulo de globais) e da visão na tela de cadastro das consultas SQL do RM, os usuários que são supervisores do módulo de globais serão notificados sobre as consultas SQL lentas que possuem em seu ambiente.
Esta informação é coletada através do Snowden e importada para serem exibidas as notificações. Ao acessar as notificações os usuários têm a possibilidade de visualizar os detalhes de cada consulta SQL lenta e assim tomar a decisão de corrigi-la, adotando as melhores práticas de construção, também poderá deixar para analisar em um segundo momento ou se preferir poderá escolher ignorar.
Exemplo de como serão exibidas as informações:
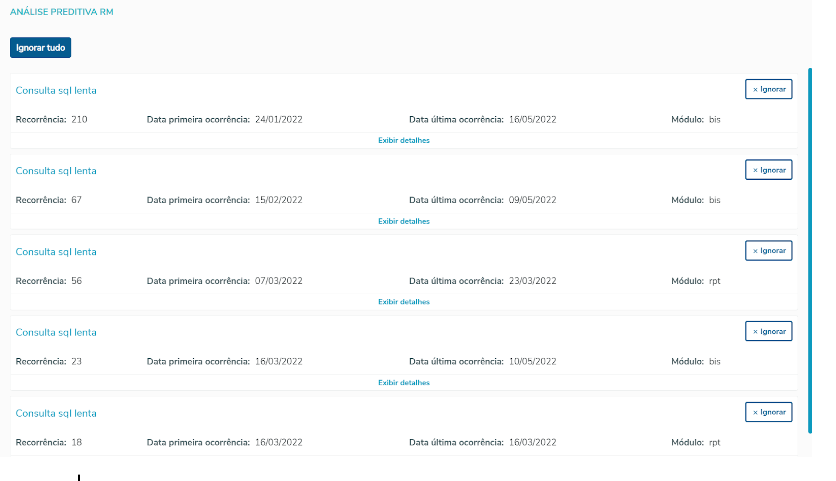
Caso escolha na tela de notificações para ignorar uma consulta SQL lenta ou todas as consultas SQL lentas, as mesmas não irão mais aparecer na tela de notificação, mas não quer dizer que as lentidões foram corrigidas. Portanto, aconselhamos marcar esta opção somente após analisar a consulta e modificá-la para ficar mais performática. Desta forma seu sistema ficará mais rápido!
Para não trazer informações pontuais, que podem ser impactadas por algum item específico no ambiente, só serão demonstradas consultas que tiverem mais de 10 recorrências no período de 3 meses.
Para localizar a consulta SQL ofensora em sua base de dados siga os passos abaixo.
Copie parte da sintaxe e utilize na busca dentro do SGBD ou menu SQL da MDI para identificar o código (desta forma é possível rastrear o uso):
SGBD:

MDI:
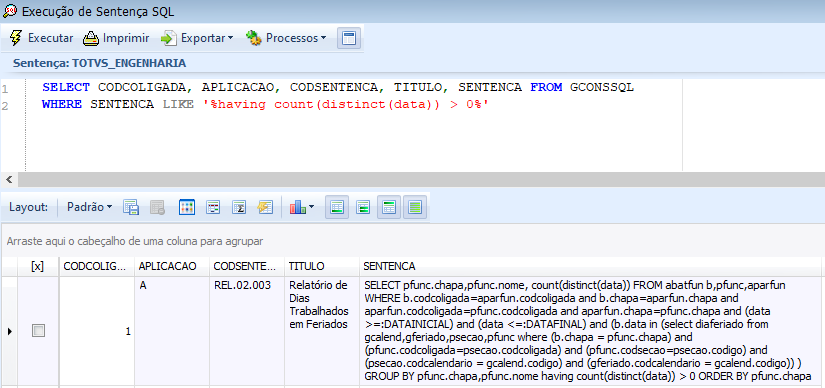
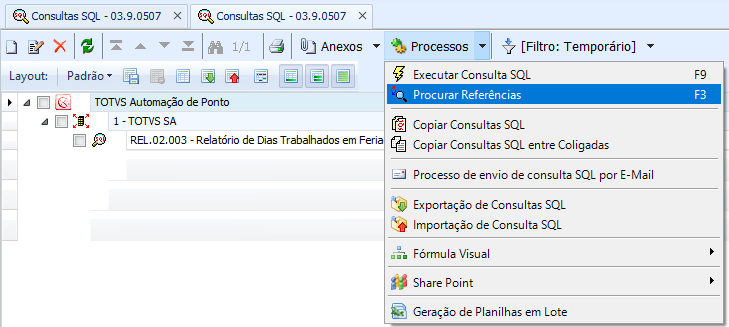
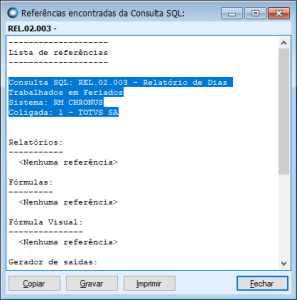
Após identificar o código, é possível rastrear onde ela é utilizada:
Consulta para Oracle
-- Criação da tabela
CREATE GLOBAL TEMPORARY TABLE MYGTT_CONSSQL (CODCOLIGADA NUMBER(5), APLICACAO CHAR(1), TITULO VARCHAR2(150), SENTENCA CLOB) ON COMMIT DELETE ROWS;
"Esta parte em destaque garante que após o 'commit' todos os dados são retirados da tabela, justamente para que seja necessário inserir novas informações a cada pesquisa"
-- Carga de dados para tabela
INSERT INTO MYGTT_CONSSQL ( SELECT CODCOLIGADA, APLICACAO, CODSENTENCA , TO_LOB(SENTENCA) FROM GCONSSQL ) ;
-- Buscar informações de acordo com sua necessidade para o campo SENTENCA que inicialmente era LONG e não permitia buscar com LIKE
SELECT * FROM MYGTT_CONSSQL WHERE SENTENCA LIKE '%having count(%';
-- Caso não precise mais da tabela em suas consultas e deseje retira-la de seu banco de dados
DROP TABLE MYGTT_CONSSQL ( caso não necessite da tabela mais );
Abaixo, elencamos boas práticas e dicas para construção de uma consulta sql:
1. Ao escrever uma cláusula WHERE, sempre colocar a cláusula mais restritiva antes. Qual é a condição mais restritiva? A condição na cláusula WHERE de uma instrução que retorna o menor número de linhas de dados.
2. Evitar cláusulas WHERE que utilizam colunas não indexadas ou solicitar a criação do índice para a equipe de banco de dados. É muito importante avaliar quais colunas da tabela serão apresentadas no resultado bem como quais colunas participam da cláusula WHERE, caso tais colunas estejam dentro de um índice ‘não clusterizado’, será o caminho mais performático para sua consulta.
Na tabela em questão temos um índice ‘nonclustered’ com as colunas chapa, anocomp, mescomp, nroperiodo e codevento. Ao montar a consulta podemos ver que imediatamente o banco de dados decidiu usá-lo para determinar a execução da consulta:
select CHAPA, ANOCOMP, MESCOMP, NROPERIODO, CODEVENTO
FROM PFFINANC
WHERE CHAPA='012000069'
AND ANOCOMP = 2022
AND MESCOMP = 1
AND NROPERIODO = 1
AND CODEVENTO = '0004'


Veja o plano de execução estimado entre as duas consultas, a diferença entre a estimativa simplesmente por ter modificado as colunas a serem retornadas:

Obs.: Caso exista colunas na cláusula select ou na where que não estejam neste índice, será necessário usar o índice da chave primária, não sendo tão performático. Ou seja, sempre dê preferência para colunas associadas aos índices ‘não clusterizados’.
3.Não esquecer de colocar (NOLOCK) nas sentenças (exceto quando se aplica exceção)
4. No SELECT, trazer apenas as colunas necessárias;
Vimos este estudo no ítem 2 deste documento, escolher as colunas prioritárias que estão citadas nos índices ‘não clusterizados’ para depois adotar as demais colunas que serão cobertas pelo índice ‘clusterizado’ referente a chave primária. Caso exista alguma coluna elegível a ser associada a algum índice ‘não clusterizado’, entre em contato conosco para avaliarmos a sugestão e apresentarmos ao produto tal oportunidade de melhoria.
Obs.: é muito importante não usar o “SELECT * FROM” nas suas consultas, sempre avaliar se precisa de todas colunas da tabela para sua análise. Pode ser que uma das colunas que seriam desnecessárias para sua pesquisa possua dados que ocuparam megas, gigas de seus recursos gerando lentidão em todo o banco de dados e sistema desnecessariamente.
5. Para Sub-Selects na cláusula WHERE, considere utilizar EXISTS ao invés de IN;
A cláusula EXISTS trabalha como um comando de decisão, caso o valor seja encontrado segundo a consulta apontada pela EXISTS, então a consulta principal será executada. Neste exemplo só vou buscar a lista de pessoas caso exista pelo menos uma pessoa com a data de nascimento dia 24/04/69:
SELECT * FROM PPESSOA (NOLOCK)
WHERE EXISTS ( SELECT TOP 1 'OK' FROM PPESSOA (NOLOCK)
WHERE DTNASCIMENTO = '1969-04-24' )
Geram o mesmo número de linhas com dois conceitos aplicados:

Obs. Uma sugestão para o uso da cláusula IN, por exemplo, tenho uma lista de palavras que preciso fixá-las no filtro, neste caso tente usar a seguinte semântica:
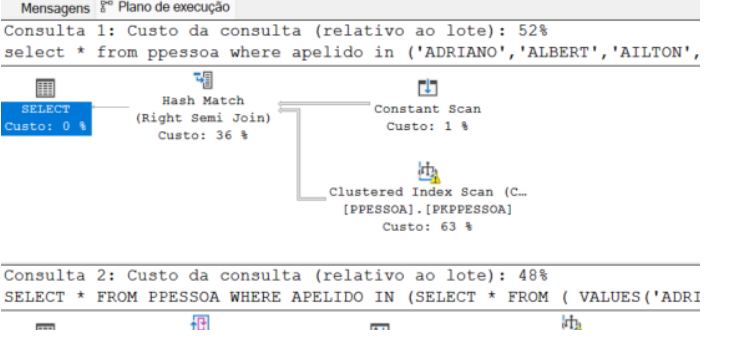
Antes: SELECT * FROM PPESSOA WHERE APELIDO IN ('EDSON','DANIEL','ANDRE')
Depois: SELECT * FROM PPESSOA WHERE APELIDO IN (SELECT * FROM ( VALUES ('EDSON'),('DANIEL'),('ANDRE') ) MINHALISTA(APELIDO))
Este ganho será evidente principalmente se a lista tiver muitos valores, no exemplo abaixo foi inserida uma lista de 673 valores e já podemos ver o ganho de 2%, sendo mais expressivo dependendo do conteúdo da tabela e o tipo de dados filtrados:
6. Between no lugar de Or/And dependendo do caso? Esta é uma dúvida que sempre aparece quando precisamos usar essa cláusula, vamos entender:
SELECT * FROM PFFINANC WHERE VALOR BETWEEN 100 AND 200
SELECT * FROM PFFINANC WHERE VALOR >= 100 AND VALOR <= 200
O predicado para essas duas consultas é o mesmo, ou seja, internamente o sgbd* entende a instrução de cima igualmente em relação a de baixo. O uso do between seria apenas para facilitar a criação da instrução, salvo o caso em que mesmo os valores das extremidades da faixa não podem entrar para o grupo apurado.
7. Order by é caro no sql.
O uso desse recurso precisa ser bem avaliado, precisa pensar se a tela a qual o conteúdo da tabela vai ser apresentada tem recursos de ordenação, caso consiga é melhor buscar toda tabela sem organizar e fazê-lo pela aplicação. O uso do ‘order by’ é bem válido quando temos uma tabela muito grande e precisamos pegar somente alguns registros ordenados, por exemplo o uso da cláusula TOP N com o complemento do ‘order by’. Em outras palavras, não vale a pena buscar milhões de registros do banco sendo que preciso buscar os 3 primeiros com valor maior ou menor:
Dicas importantes:
- Tente não usar função agregada no order by, por exemplo
ORDER BY CAST(COLUNA AS VARCHAR(10)) DESC
- Ao fazer um insert com o resultado de um select, nunca use o order by nesse select:
INSERT INTO TABELA1
SELECT COLUNA1, COLUNA2 FROM TABELA2 ORDER BY COLUNA1 DESC
8. De preferência em usar JOIN no lugar de UNION. Vamos entender as diferenças entre estas cláusulas para conseguir aplicá-las sem perder a performance e objetivo da consulta:
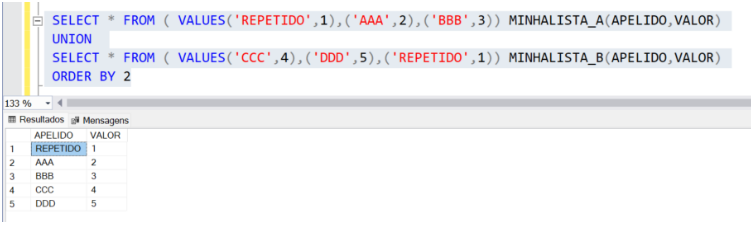
No caso do ‘Union’, serve principalmente para unificar linhas entre duas tabelas que possuem mesmas colunas e unificar as linhas que são idênticas entre ambas. Veja que o objetivo foi atingido listando todas as linhas das tabelas eliminando as repetições:
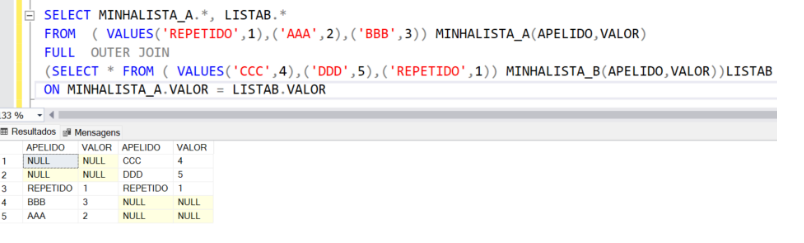
No caso do ‘Join’, estamos falando de junções horizontais as quais podemos mesclar informações de ambas tabelas. Nesta cláusula usamos o conceito de conjuntos (união, intersecção e diferença), precisamos que ao menos uma coluna seja equivalente em ambas tabelas para gerar nossa expressão.
9. Não use Distinct, tente utilizar Group By no lugar. Sabemos que cada um tem seu propósito e dependendo da situação não poderemos substituir um pelo outro. Contudo se houver oportunidade de fazê-lo, tente aplicar.
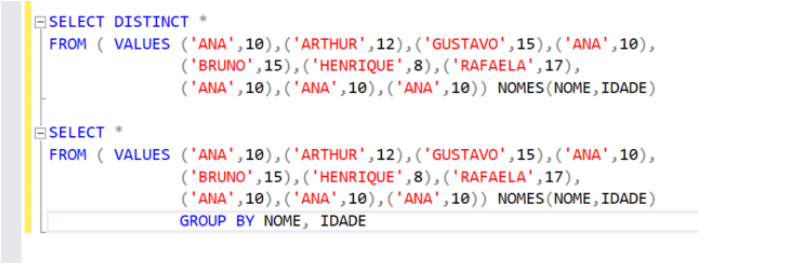
Obs.: Sempre analise o ‘plano de execução’ entre as duas abordagens, optando em adotar o item que gerou menor custo.
10. Análise o plano de execução estimado da consulta;
O plano de execução é um ótimo aliado para avaliar as condições de performance em seus comandos, quando possível utilize até mesmo o plano de execução real para que receba a informação concretizada sobre suas consultas:

Obs.: O plano de execução estimado não consegue obter resultados de leitura em disco e demais recursos envolvidos na busca das informações do disco para apresentação na tela ao que o ‘plano de execução real’ assiste tais métricas.
Outro ponto importante sobre o uso do ‘plano de execução estimado’ é que ele se baseia nas estatísticas da base de dados, caso elas estejam desatualizadas, teremos problemas na composição deste plano.
11. Utilize flags de tipo booleano ou inteiro (colunas deste tipo), o Oracle não possui este tipo, portanto, utilize o tipo numeric (0 ou 1);
12. Evite utilizar conversões com UPPER, TO_CHAR e etc em cláusulas WHERE, esta operação faz com que o banco de dados naturalmente ignore a utilização dos índices automáticos criados para estas colunas, que tornariam a consulta bem mais rápida.
Observe a imagem abaixo, seria a mesma consulta que gera o mesmo resultado, mas com alguns pontos de atenção a serem observados no uso de funções na cláusula where:
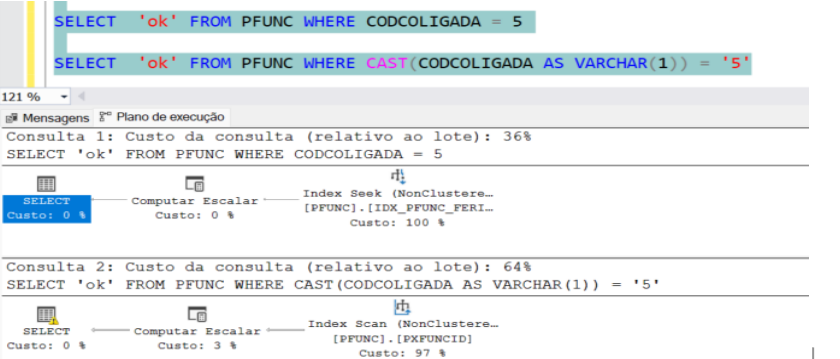
Podemos ver que nativamente o índice ‘não clusterizado’ foi escolhido na primeira busca pois a coluna estava associada a este índice, com essa decisão ele conseguiu fazer uma busca ‘seek’ que é mais direcional para encontrar o valor necessário.
Na segunda consulta o usuário decidiu fazer uma conversão do tipo de dados. Neste momento o sgbd* decidiu utilizar o índice da chave primária para buscar toda a tabela e fazer um ‘scan’ até encontrar o valor necessário.
Conclusão: Avalie muito se é possível não inserir expressões com funções as quais retiram uma busca ‘seek’ num índice ‘não clusterizado’ na coluna presente dentro da cláusula where. Pesquise algo referente a consultas NoSarg e Sarg (termo Search Argument Table).
13. Não utilize HAVING para filtrar dados, caso necessite filtrar dados em um agrupamento de informações, prefira sempre realizar esta operação na cláusula WHERE ao invés do HAVING, por questões de performance, a não ser que seja necessário realizar algum filtro utilizando realmente as operações de agregação;
- Na maioria dos casos em que não existe a necessidade de agregação, o filtro Where atende a regra de filtragem na consulta, caso necessite agrupar algum cálculo veja a possibilidade em usar também o filtro Where.
- Uso do ‘SET NOCOUNT ON’, consegue visualizar ganhos?
Em muitos casos um comando executado por ‘stored procedure’ pode gerar grande fluxo de informações na rede e que talvez não ser usado para qualquer regra.
Durante ‘updates’, por exemplo, na maioria dos casos não capturamos o valor das linhas afetadas, sendo gerado um fluxo de informações desnecessárias.
Esse recurso se torna valioso quando abrimos transações demoradas se dispensamos o retorno de quantas linhas foram afetadas após o ‘commit’
14. Dica importante para consultas que possuem filtros criados dinamicamente e que acabam gerando uma sequência de operadores lógicos ( OR, AND), tornando-a muito lenta e até mesmo não executável:
Para este tipo de situação uma solução bem adequada seria o uso de CTE para montar o filtro desejado, vejamos o exemplo abaixo:
- Antes de aplicar a CTE:
SELECT * FROM TMOV WHERE
( CODCOLIGADA = 1 AND IDMOV = 10 )
OR ( CODCOLIGADA = 1 AND IDMOV = 20 )
OR ( CODCOLIGADA = 1 AND IDMOV = 30 )
OR ( CODCOLIGADA = 1 AND IDMOV = 40 ) ...
- Depois de aplicar a CTE:
WITH CTE_FILTRO_IDMOV AS ( SELECT * FROM (VALUES (1,10),(1,20),(1,30),(1,40)) FILTRO(CODCOLIGADA,IDMOV))
SELECT * FROM TMOV
JOIN CTE_FILTRO_IDMOV
ON TMOV.CODCOLIGADA = CTE_FILTRO_IDMOV.CODCOLIGADA
AND TMOV.IDMOV = CTE_FILTRO_IDMOV.IDMOV
Este recurso também está disponível em Oracle com algumas poucas diferenças, como por exemplo:
WITH
CTE_FILTRO_IDMOV AS (
SELECT 1 CODCOLIGADA, 10 IDMOV FROM DUAL
UNION
SELECT 1 CODCOLIGADA, 20 IDMOV FROM DUAL)
SELECT * FROM TMOV
JOIN CTE_FILTRO_IDMOV
ON TMOV.CODCOLIGADA = CTE_FILTRO_IDMOV.CODCOLIGADA
AND TMOV.IDMOV = CTE_FILTRO_IDMOV.IDMOV
Explore o uso da CTE em suas consultas!
Legenda:
SGBD = Gerenciamento de Banco de Dados (SGBD) – do inglês Data Base Management System (DBMS)
Mais informações sobre consultas SQL's podem ser acessadas em https://tdn.totvs.com/display/LRM/Trabalhando+com+Consultas+SQL
Caso você precise de apoio para a realização dos ajustes procure o time de Consultoria TOTVS através do link abaixo:
Visão Geral
Import HTML Content
Conteúdo das Ferramentas
Tarefas